Java Spark Partition by Example
Apache Spark's Resilient Distributed Datasets (RDD) are a collection of various data that are so big in size, that they cannot fit into a single node and should be partitioned across various nodes. Apache Spark automatically partitions RDDs and distributes the partitions across different nodes. They are evaluated lazily (i.e, the execution will not start until an action is triggered which increases manageability, saves computation and thus increases optimization and speed) and the transformations are stored as directed acyclic graphs (DAG). So, every action on the RDD will make Apache Spark recompute the DAG.
It's important to understand the characteristics of partitions in Apache Spark so that it will guide you in achieving better performance, debugging and error handling.
Here are some of the basics of partitioning:
- Every node in a Spark cluster contains one or more partitions.
- The number of partitions used in Spark is configurable and having too few (causing less concurrency, data skewing and improper resource utilization) or too many (causing task scheduling to take more time than actual execution time) partitions is not good. By default, it is set to the total number of cores on all the executor nodes.
- Partitions in Spark do not span multiple machines.
- Tuples in the same partition are guaranteed to be on the same machine.
- Spark assigns one task per partition and each worker can process one task at a time.
Hash partitioning vs. range partitioning in Apache Spark
Apache Spark supports two types of partitioning "hash partitioning" and "range partitioning". Depending on how keys in your data are distributed or sequenced as well as the action you want to perform on your data can help you select the appropriate techniques. There are many factors which affect partitioning choices like:
- Available resources — Number of cores on which task can run on.
- External data sources — Size of local collections, Cassandra table or HDFS file determine number of partitions.
- Transformations used to derive RDD — There are a number of rules to determine the number of partitions when a RDD is derived from another RDD.
As you can see there are multiple aspects you'll need to keep in mind when working with Apache Spark. In this blog, I want to highlight the importance of being completely aware of your business data, its keys and physical resources on Spark processing, most importantly network, CPU and memory.
Let's look at some common pitfalls when working with Apache Spark partitioning:
Skewed data and shuffle blocks
Processing with Apache Spark's default partitioning might cause data to be skewed which, in turn, can cause problems related for shuffle during aggregation operations or single executor not having sufficient memory.
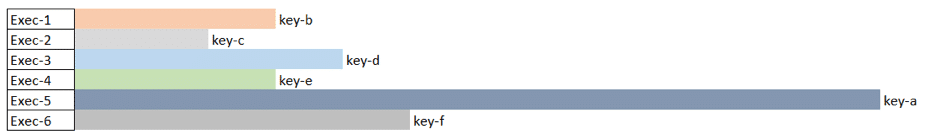
Example of Skewed Data
Here we see "key-a" has a larger amount of data in the partition so tasks on Exec-5 will take much longer to complete than the other five tasks. Another important thing to remember is that Spark shuffle blocks can be no greater than 2 GB (internally because the ByteBuffer abstraction has a MAX_SIZE set to 2GB). For example, if you are running an operation such as aggregations, joins or cache operations, a Spark shuffle will occur and having a small number of partitions or data skews can cause a high shuffle block issue. Hence, if you started seeing an error related to breach of MAX_SIZE limits due to shuffle you know why it's happening as it may be tied to skewed data.
Partition wisely
So how do you avoid skewed data and shuffle blocks? Partitioning wisely. It's critical to partition wisely in order to manage memory pressure as well as to ensure complete resource utilization on executor's nodes. You must always know your data — size, types, and how it's distributed. A couple of best practices to remember are:
- Understanding and selecting the right operators for actions like reduceByKey or aggregateByKey so that your driver is not put under pressure and the tasks are properly executed on executors.
- If your data arrives in a few large unsplittable files, the partitioning dictated by the InputFormat might place large numbers of records in each partition, while not generating enough partitions to take advantage of all the available cores. In this case, invoking repartition with a high number of partitions after loading the data will allow the operations that come after it to leverage more of the cluster's CPU.
- Also, if data is skewed then repartitioning using an appropriate key which can spread the load evenly is also recommended.
Talend provides atPartition component for repartitioning needs based on appropriate keys you choose.
How do you get the right number of partitions?
Apache Spark can only run a single concurrent task for every partition of an RDD, up to the number of cores in your cluster (and probably 2-3x times that). Hence as far as choosing a "good" number of partitions, you generally want at least as many as the number of executors for parallelism. You can get this computed value by calling sc.defaultParallelism. The maximum size of a partition is ultimately limited by the available memory of an executor.
There are also cases where it's not possible to which understand proper repartitioning key should be used for even data distribution. Hence, methods like Salting can be used which involves adding a new "fake" key and using alongside the current key for better distribution of data. Here's an example:
- Add a random element to large RDD and create new join key with it like "Salting key = actual join key + Random fake key where fake key takes value between 1 to N, with N being the level of distribution"
- Add a random element to small RDD using a Cartesian product (1-N), to increase the number of entries and create new join key
- Join RDDs on a new join key which will now be distributed better due to random seeding.
- Remove the random fake key from the join key to get the final result of the join
In the example above, the fake key in the lookup dataset will be a Cartesian product (1-N), and for the main dataset, it will a random key (1-N) for the source data set on each row, and N being the level of distribution.
Talend and Apache Spark
Talend Studio provides graphical tools and wizards that generate native code so you can start working with Apache Spark, Spark Streaming and even partitioning your data properly. The above techniques can be implemented usingtMap component from Talend. You can also fulfill repartitioning needs with the tPartition componentin Talend if you know the data well and our tMap component for performing salting and random number techniques for concerns on data having keys which are skewed or null values as appropriate.
I hope you learned something new about the basics of Apache Spark partitioning and processing in this short blog post. For more information on how Talend and Apache Spark work together to help speed and scale your big data processing, you can visit our solutions page.
References:
https://issues.apache.org/jira/browse/SPARK-6235
https://0x0fff.com/spark-architecture
https://www.youtube.com/watch?v=WyfHUNnMutg
http://blog.cloudera.com/blog/2015/05/working-with-apache-spark-or-how-i-learned-to-stop-worrying-and-love-the-shuffle/
http://blog.cloudera.com/blog/2015/03/how-to-tune-your-apache-spark-jobs-part-1/
https://stackoverflow.com/questions/40373577/skewed-dataset-join-in-spark
Ready to get started with Talend?
Source: https://www.talend.com/resources/intro-apache-spark-partitioning/
0 Response to "Java Spark Partition by Example"
Post a Comment